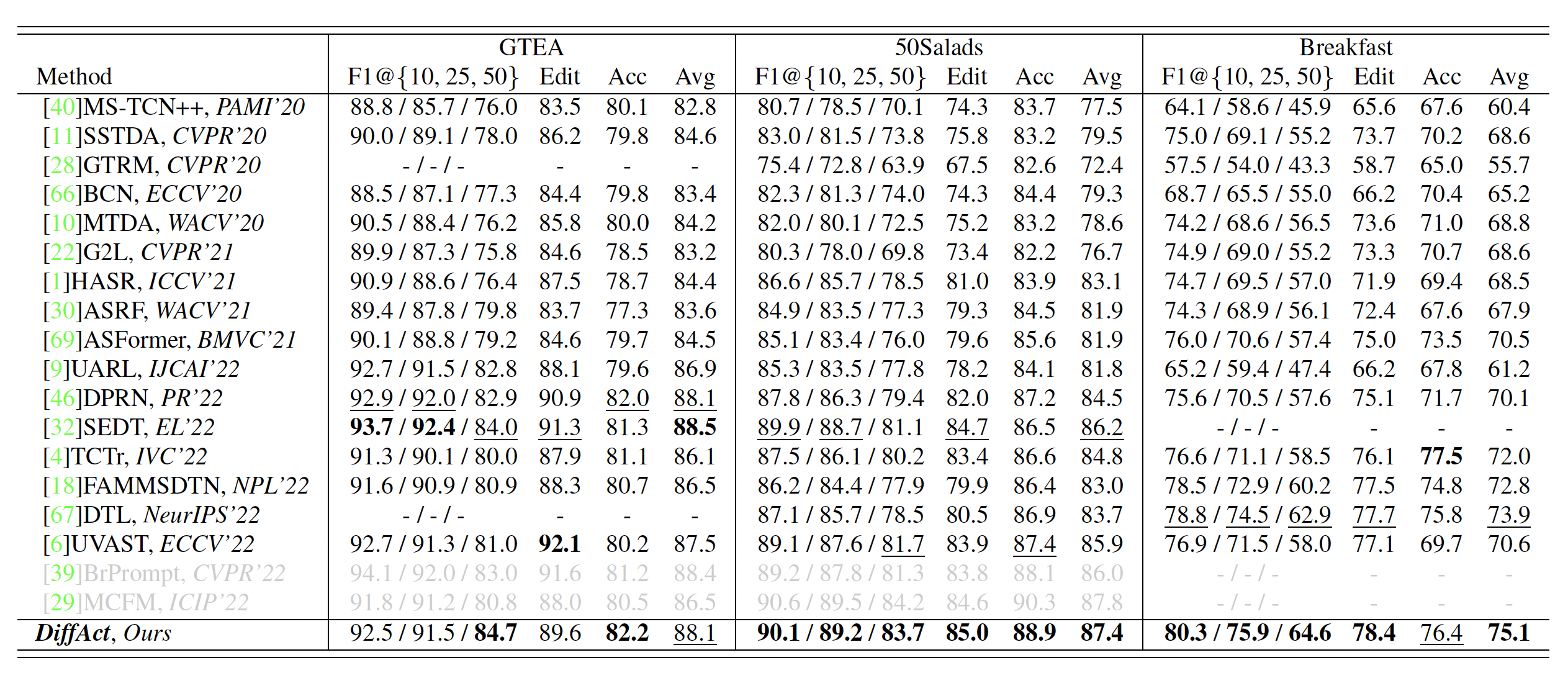
Temporal action segmentation is crucial for understanding long-form videos. Previous works on this task commonly adopt an iterative refinement paradigm by using multi-stage models. We propose a novel framework via denoising diffusion models, which nonetheless shares the same inherent spirit of such iterative refinement. In this framework, action predictions are iteratively generated from random noise with input video features as conditions. To enhance the modeling of three striking characteristics of human actions, including the position prior, the boundary ambiguity, and the relational dependency, we devise a unified masking strategy for the conditioning inputs in our framework. Extensive experiments on three benchmark datasets, i.e., GTEA, 50Salads, and Breakfast, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action segmentation.
@inproceedings{liu2023diffusion,
title={Diffusion Action Segmentation},
author={Liu, Daochang and Li, Qiyue and Dinh, Anh-Dung and Jiang, Tingting and Shah, Mubarak and Xu, Chang},
booktitle={International Conference on Computer Vision (ICCV)},
year={2023}
}